Kernel - Processes and threads - Message passing
Message passing is the fundamental functionality of the operating system kernel which acts as a basic method of interaction between operating system components. Message passing in Phoenix-RTOS is synchronous. Sending thread is suspended until the receiving thread receives a message and responds to it.
Ports
Port is the communication endpoint used for passing messages between executed threads.
Data transfer
Kernel implements message passing by the following functions.
extern int proc_send(u32 port, msg_t *msg);
extern int proc_recv(u32 port, msg_t *msg, unsigned int *rid);
extern int proc_respond(u32 port, msg_t *msg, unsigned int rid);
Structure msg_t identifies message type and consists of two main parts - input part and output part.
Input part points to the input buffer and defines its size. It contains also a small buffer for passing the message application header. The output part has symmetrical architecture to input buffer. It contains the pointer to output buffer, output buffer data length and buffer for output application header.
When message is sent by the proc_send function the sending thread is suspended until the receiving thread executes
proc_recv function, reads data from input buffer, writes the final answer to the output buffer and executes
proc_respond. The rid word identifies the receiving context and should be provided to the proc_respond function.
There is possible to execute a lot of instructions between receiving and responding procedures. Responding function is
used to wake up the sending thread and inform it that data in output buffer are completed.
To prevent copying of big data blocks over the kernel when communication goes between threads assigned to separate processes special optimization is introduced. When message is received by the receiving thread input and output buffers are transparently mapped into the receiver address space. To prevent interference with other data, if any of these buffers is not aligned with the page, the heading or tailing part of this buffer is copied to the newly allocated page mapped instead of the original page. When receiving thread responses to the message the buffers are unmapped and heading or tailing parts are copied to the original page located in sender address space. This technique is briefly presented on following figure.
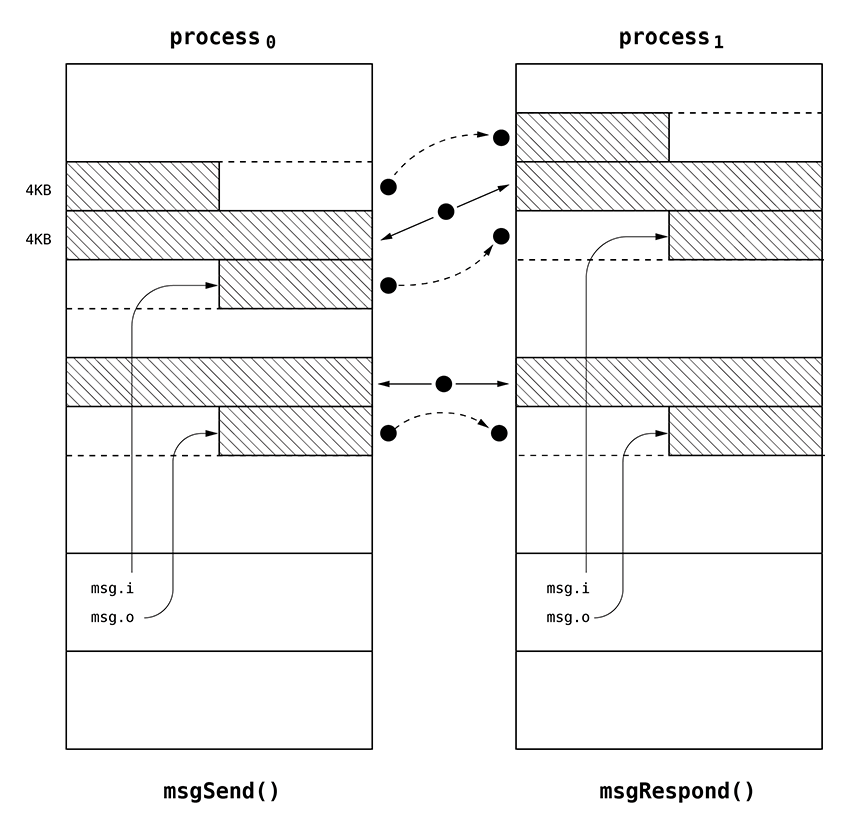
There is another type of optimization. If input or output data size is lower than page size and data fits into the buffer used for application header passing the data is copied instead of using virtual memory capabilities which provide extra overhead for small messages.